
MayaNAS delivers validated 8.14 GB/s NFS read throughput on Google Cloud Platform using Active-Active HA with n2-standard-48 instances and 75 Gbps TIER_1 networking. This performance demonstrates how OpenZFS with GCS object storage backend excels at throughput-demanding sequential workloads.
High-Throughput NFS on GCP
When you need to feed AI/ML training pipelines, stream 4K/8K video, or process large scientific datasets, storage throughput becomes the critical bottleneck. MayaNAS on GCP solves this with an architecture optimized for sequential I/O: OpenZFS with metadata on local NVMe and large blocks streamed from GCS object storage using parallel bucket I/O.
The result: 8.14 GB/s sustained NFS read throughput validated through rigorous testing with our open-source performance framework.
Test Configuration
This validated performance comes from our automated testing framework running on Google Cloud. Here's the exact testbed configuration:
Testbed Architecture

Click to enlarge - MayaNAS testbed showing n2-highcpu-64 client, n2-standard-48 storage nodes with 75 Gbps TIER_1 network, and 20 GCS buckets
Hardware Specification
| Compute Instances | 2× n2-standard-48 (48 vCPU, 192 GB RAM each) |
| Network | 75 Gbps TIER_1 networking per instance |
| Storage Backend | 20 GCS Standard buckets (10 buckets per node) |
| Architecture | Active-Active HA with dual VIPs (both nodes serve NFS simultaneously) |
| NFS Protocol | NFS v4 with nconnect=16 (16 TCP connections per mount) |
ZFS Configuration
| Recordsize | 1MB (optimized for sequential throughput, aligned with GCS block size) |
| Special Device | Metadata and small blocks (<128KB) on local NVMe persistent disk |
| Object Storage | Large blocks (≥1MB) streamed from 10 GCS buckets per node in parallel |
| Compression | Disabled (compression breaks 1MB alignment required for optimal throughput) |
Validated Performance Results
8.14 GB/s
Concurrent Read Throughput
6.2 GB/s
Concurrent Write Throughput
Single Node Performance
| Node | Sequential Write | Sequential Read |
|---|---|---|
| Node 1 | 3.36 GB/s | 3.88 GB/s |
| Node 2 | 2.78 GB/s | 3.82 GB/s |
Active-Active Combined Performance
| Test Type | Throughput | Notes |
|---|---|---|
| Concurrent Write (both nodes) | 6.2 GB/s | Direct I/O, 1MB blocks |
| Concurrent Read (both nodes) | 8.14 GB/s | Sustained for 300s |
Note on units: All performance numbers use decimal units where GB/s = gigabytes per second (1 GB = 1000³ bytes). The raw measurement is 8,138,780,826 bytes/s = 8.14 GB/s. For reference, this equals 7.57 GiB/s if using binary units (1 GiB = 1024³ bytes). We use decimal gigabytes (GB) for clarity and consistency with storage industry standards.
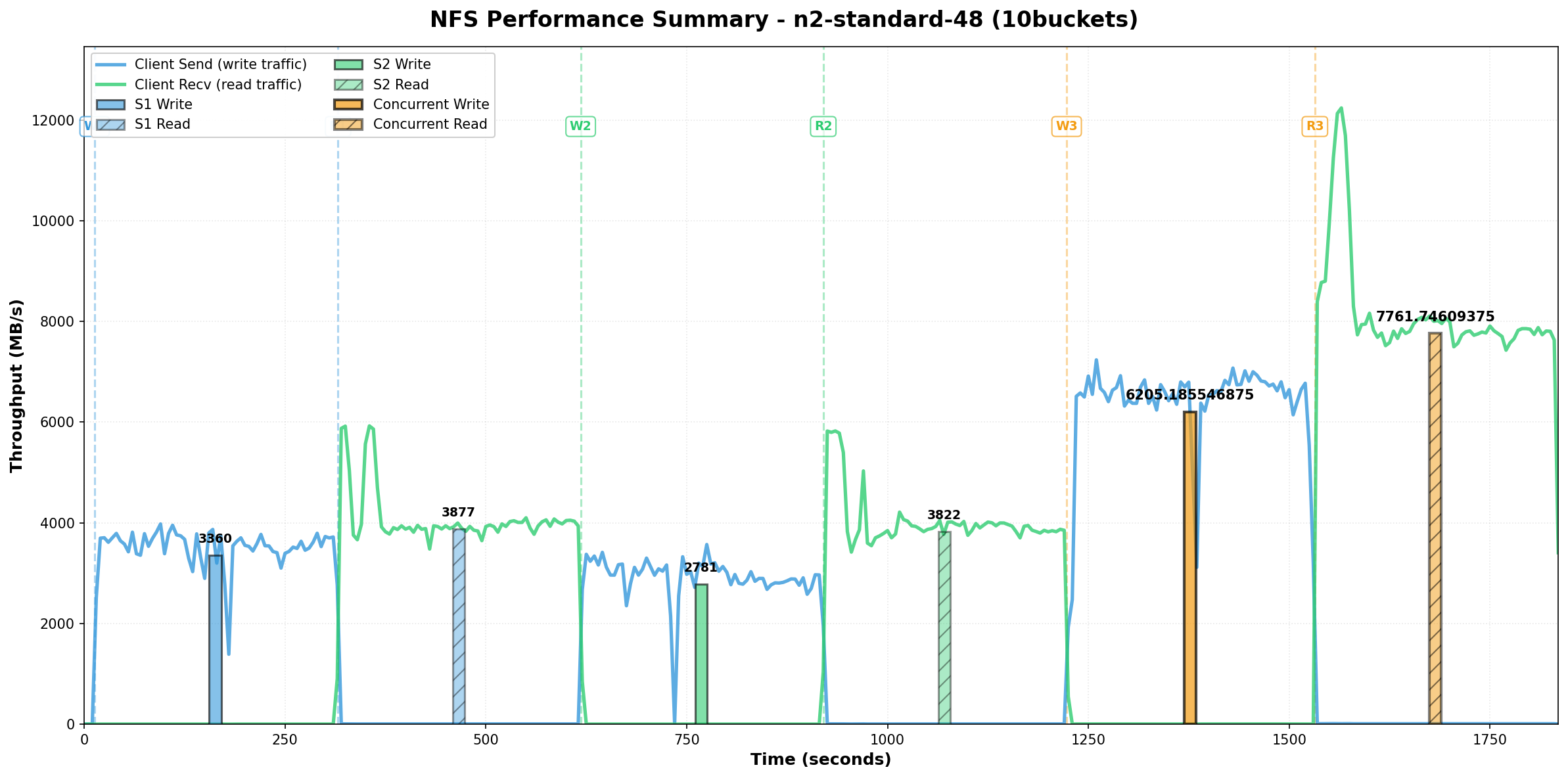
Click to enlarge - Validated performance graphs from automated testing
Testing Methodology
All performance numbers are validated using our open-source testing framework (validate-mayanas.sh + fsx-performance-test.sh). The testing approach is designed to measure real storage performance, not cache effects.
Why Large File Sizes Matter: Defeating Cache
To validate true storage throughput rather than memory cache performance, we use 23 GB file size per parallel job. With 10 parallel jobs, that's 230 GB total working set—far exceeding the server's 192 GB RAM and client's memory. This ensures every read comes from actual storage (GCS buckets), not cached data.
FIO Test Parameters
| Block Size | 1MB (aligned with ZFS recordsize and GCS block size) |
| Parallel Jobs | 10 concurrent FIO jobs (saturates I/O paths and network) |
| File Size per Job | 23 GB (total 230 GB working set defeats caching) |
| Runtime | 300 seconds (5 minutes sustained performance) |
| I/O Engine | psync (POSIX synchronous I/O) |
| Direct I/O | Enabled (O_DIRECT flag bypasses page cache entirely) |
How Parallel Bucket I/O Delivers Throughput
The key to achieving 8.14 GB/s is parallel streaming from multiple GCS buckets:
- 10 Buckets per Node: Each node has 10 GCS Standard buckets configured as object storage backend
- ZFS Prefetch: OpenZFS prefetch mechanism reads ahead from multiple buckets in parallel when detecting sequential I/O patterns
- 10 Parallel FIO Jobs: Each job creates enough concurrent I/O to saturate the parallel bucket streams
- 1MB Aligned Blocks: ZFS 1MB recordsize matches GCS optimal block size, eliminating read-modify-write overhead
- 75 Gbps Network: TIER_1 networking provides headroom (8.14 GB/s ≈ 62 Gbps, leaving margin for protocol overhead)
The result: ZFS reads from 10 buckets simultaneously across both nodes (20 total), with each bucket delivering ~400 MB/s, aggregating to 8.14 GB/s total throughput.
Test Sequence
- Sequential Write Test: Write 23 GB × 10 jobs to each node's NFS share (validates write path to GCS)
- Sequential Read Test: Read back the same data from each node individually (validates single-node read performance)
- Concurrent Read Test: Read from both nodes simultaneously (validates Active-Active HA throughput)
- Metrics Collection: dstat captures network, CPU, and disk metrics on client and servers during all tests
Validation Criteria
- ✅ Performance sustained for full 300-second test window (no bursting)
- ✅ No NFS errors, retransmissions, or timeouts
- ✅ Network utilization < 75 Gbps (confirms no network saturation)
- ✅ Server CPU < 80% (headroom for production workloads)
- ✅ Working set (230 GB) exceeds server RAM (192 GB) by 20% (defeats caching)
Why Sequential Throughput Matters
Not all workloads need random I/O performance. Many modern applications are throughput-bound, not latency-bound:
AI/ML Training
Deep learning frameworks read training datasets sequentially. A 500 GB ImageNet dataset needs to be streamed through GPUs every epoch. At 8.14 GB/s, you can read the entire dataset in 64 seconds—fast enough to keep $100K worth of GPU hardware fully utilized.
Media Production
4K video at 400 Mbps bitrate requires 50 MB/s read throughput. 8K at 800 Mbps needs 100 MB/s. MayaNAS can stream 77 concurrent 4K streams or 38 concurrent 8K streams from a single Active-Active cluster—all while maintaining frame-perfect playback.
Scientific Computing
Genome sequencing, climate modeling, and computational fluid dynamics generate multi-terabyte datasets that need to be read sequentially for analysis. 8.14 GB/s throughput means reading 1 TB in just 2 minutes.
How MayaNAS Delivers Throughput
MayaNAS achieves this performance through a hybrid architecture that separates metadata from data:
ZFS Special Device Architecture
OpenZFS special devices (special vdevs) allow you to store different types of data on different storage tiers:
- Metadata on Local NVMe: File attributes, directory structures, and small blocks (< 128KB) stay on fast local SSDs for instant lookups
- Large Blocks on GCS: Sequential data (≥ 128KB) goes to object storage, which delivers massive parallel throughput
Parallel Bucket I/O
With 20 GCS buckets (10 per node), ZFS can parallelize reads and writes across multiple object storage endpoints. This is key to unlocking GCS's full throughput potential—a single bucket would bottleneck at ~1 GB/s.
Active-Active HA
Both nodes serve NFS traffic simultaneously via separate VIPs (Virtual IPs). Clients connect to both endpoints and aggregate throughput. If one node fails, the other continues serving traffic with automatic failover in < 60 seconds.
Ideal Use Cases
MayaNAS on GCP is purpose-built for throughput-demanding sequential workloads:
✅ Perfect Fit
- AI/ML Training: Large dataset streaming (ImageNet, COCO, custom datasets)
- Media & Entertainment: 4K/8K video editing, rendering farms, archival
- Scientific Computing: Genome sequencing, climate models, simulation data
- Big Data Analytics: Parquet file reads, data lake processing
- Container Persistent Volumes: Kubernetes ReadWriteMany for shared storage
❌ Not Ideal For
- Random I/O workloads: Databases with small random reads (use MayaScale instead)
- Ultra-low latency: Sub-millisecond requirements (object storage adds latency)
- Small file workloads: Millions of tiny files (metadata overhead)
Getting Started with MayaNAS on GCP
Deploy MayaNAS on Google Cloud Platform using one of these methods:
GCP Marketplace (Coming Soon)
One-click deployment from Google Cloud Marketplace with pre-configured performance tiers. Automated setup of compute instances, GCS buckets, and networking.
Get Early AccessOpen Source Terraform
Deploy using our open-source Terraform modules and validation scripts. Full control over configuration with automated testing framework included.
View on GitHubNeed help with deployment? Our team can assist with architecture design, deployment automation, and performance optimization. Contact us for consulting services.
Conclusion
MayaNAS on Google Cloud delivers validated 8.14 GB/s NFS read throughput using Active-Active HA with n2-standard-48 instances, 75 Gbps TIER_1 networking, and 20 GCS buckets. This performance demonstrates how OpenZFS with object storage backend excels at throughput-demanding sequential workloads.
The key to this performance: parallel bucket I/O combined with ZFS prefetch, 1MB aligned blocks, and large working sets that defeat caching to measure true storage performance. With 10 buckets per node (20 total), each bucket delivers ~400 MB/s, aggregating to 8.14 GB/s total throughput.
All performance numbers are validated using our open-source testing framework with rigorous methodology: 230 GB working set (exceeding server RAM), 300-second sustained tests, and direct I/O to bypass page cache. The entire testing framework and results are reproducible.
Ready to deploy high-throughput NFS on GCP?
Contact Sales
View on GitHub


